
Utredningen fastnar i utrednings göraren 3: Att samla egen statistik
Den här serien blogginlägg är en ansats att undersöka siffrorna bakom den könsbekräftande vården av vuxna i Sverige. Serien består av fem delar. I den första delen introducerade jag kort vad en könsidentitetsutredning är och hur den sitter ihop med svensk lagstiftning, vem som går igenom den och varför. Eftersom jag är datavetare kommer jag att beskriva processerna här ur det perspektivet – som en pipeline med parallella inslag. Jag kommer också delvis att använda datavetenskapliga metoder för att diskutera egenskaper hos processerna.
I den andra delen försökte jag säga något om hur många som berörs av situationen med hjälp av offentligt publicerade siffror. Det är så att säga det ytligaste möjliga grävet.
I den här delen, den tredje, presenterar jag en enkätundersökning jag gjort. I den fjärde delen sammanställer jag siffror för bland annat väntetider, och i den femte delen sätter jag siffrorna i sin kontext, diskuterar vad som händer nu, och jämför med min egen situation som exempel.
Eftersom jag inte kunde få tag på tillräckligt detaljerad statistik från offentliga källor startade jag också en insamling via en enkät online. Enkäten är medvetet konstruerad med så enkla metoder som möjligt enligt principen att kod som inte finns där inte kan ha en bugg. I synnerhet var det viktigt för mig att inte samla in personuppgifter, eftersom alla uppgifter — även “IP-nummer X laddar sidan vid tid Z” — är potentiellt känsliga och därför starkt skyddade eller t.o.m olagliga att samla in.
Av den anledningen såg jag till att göra en webbsida som bara kör kod jag skrivit, och så lite som möjligt av den. Jag såg också till att ladda all kod från min egen server som jag kör hemma på en avlagd laptop i en byrålåda för att garantera att ingen information passerar okrypterat via en tredje part. Allt det här kan tyckas onödigt paranoidt, och det är det nästan garanterat, men jag ville också vara säker på att alla som ville lämna uppgifter kunde göra det, även de som hade mycket, mycket högre trösklar än jag själv.
För att den som lämnat en uppgift ska kunna uppdatera den i framtiden behövde jag ett opersonligt sätt att låta dem identifiera sig. För att garantera anonymitet gav jag respondenter en möjlighet att välja mellan att ange en pseudonym som bara jag och de känner till. För att undvika att alla bara skriver in sitt namn eller sin mejl (och därmed skapar personuppgifter som jag måste skrubba bort från mina hårddiskar med klor) lät jag formuläret fylla i en kod på tre tecken som standard och låta användare som hade en egen kod i åtanke ändra den. Hittills har exakt en användare gjort det.
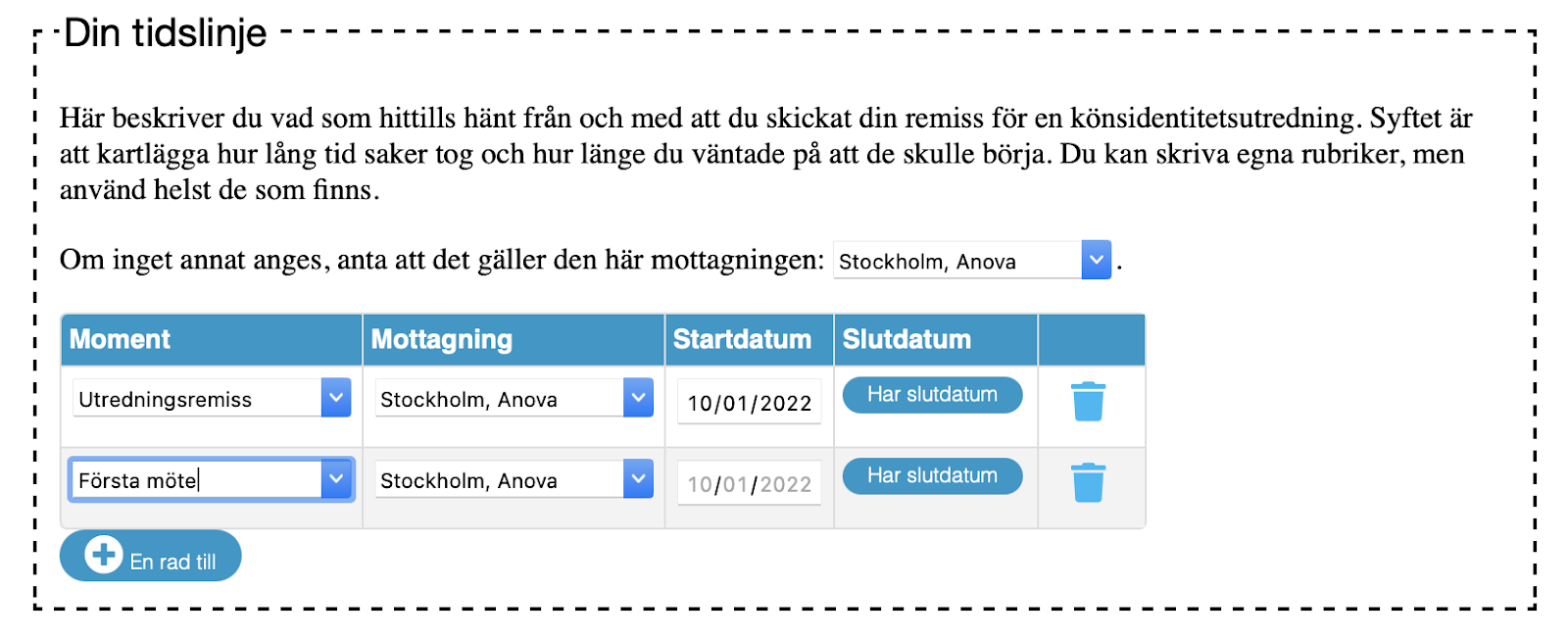
Formuläret innehåller över huvud taget ingen validering för att undvika att den vars upplevelse inte stämmer med mina förväntningar ändå ska kunna fylla i det. Däremot har jag konfigurerat webbservern till att begränsa hur många gånger ett givet IP-nummer kan skicka in det för att förhindra spam (ett problem som hittills inte dykt upp). Jag valde den lösningen för att undvika att behöva införa ett system med sessioner för användare, som annars skulle kunna introducera personuppgifter — och så vidare.
Problemet är en moment-22-situation: för att kunna använda tekniker som t.ex kakor eller koder för att motverka CSRF-attacker behöver jag introducera en session. För att den sessionen ska ha någon mening måste den kopplas till något som unikt identifierar en användare, t.ex en IP-adress. Men om jag gör det kopplar jag IP-adressen till en specifik instans av att ha laddat eller skickat formuläret, vilket i sin tur är en personuppgift och i värsta fall skulle underminera hela tanken om att formuläret är en svartkastlåda.
Min lösning på problemet blev att helt enkelt inte skydda mig mot CSRF. En CSRF-attack kan ändå som värst lura en användare att skicka mitt formulär, och eftersom jag inte gör någon skillnad på användare och inte har sessioner i någon form spelar det ingen roll vem som skickar formuläret. Det enda användningsområdet för det skulle vara för att spamma formuläret — och det har jag redan skydd mot. Det skyddet kräver i och för sig också en introduktion av konceptet användare, men eftersom det händer i webbservern och inte i min kod betyder det att datan är längre ifrån varandra. Jag tror också att nginx av effektivitetsskäl använder någon typ av imprecis metod.
I den här serien presenterar jag min egen enkätstudie.